
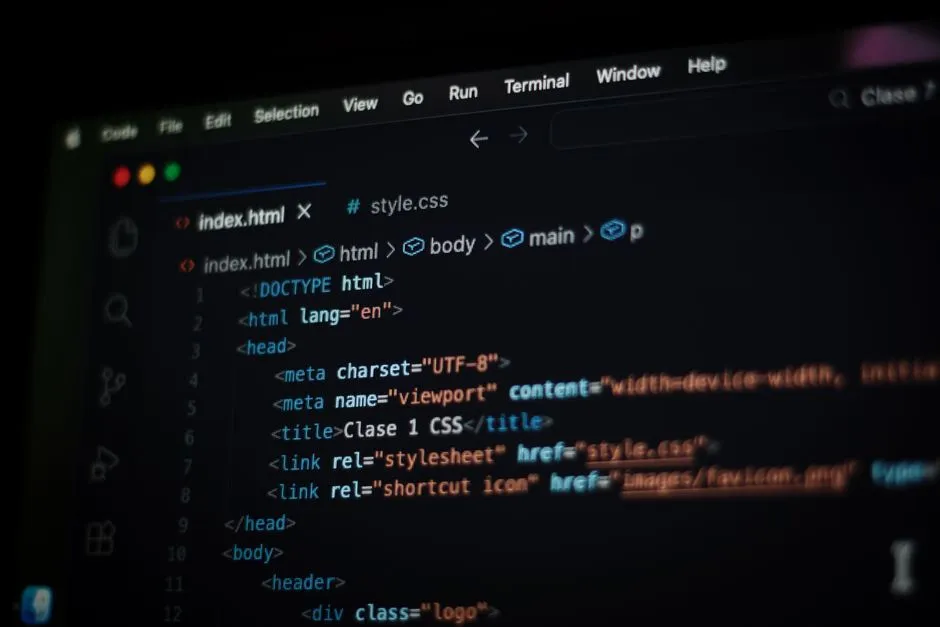
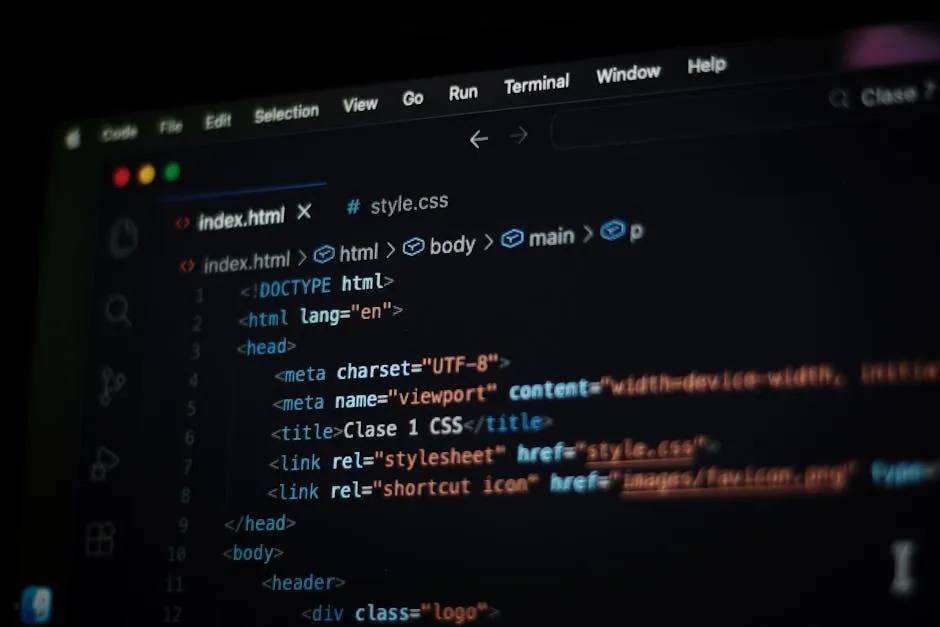
Playwright CLI vs MCP: Nên Dùng Gì Với Claude Code?
So sánh Playwright CLI và Playwright MCP server cho Claude Code: khác biệt về cơ chế, khi nào agent nên gọi thẳng CLI để tiết kiệm token thay vì qua MCP.
15 thg 7, 20265 phút đọc
Introducing ChatGPT Go, now available worldwide
A business that scales with the value of intelligence
Our approach to age prediction
ServiceNow powers actionable enterprise AI with OpenAI
Horizon 1000: Advancing AI for primary healthcare
Introducing Edu for Countries
How Higgsfield turns simple ideas into cinematic social videos
Inside GPT-5 for Work: How Businesses Use GPT-5

Claude Code có thể tự động retry đến khi hết token limit và đốt hàng chục đô âm thầm. Bài viết chỉ ra pattern đốt tiền và 5 chốt chặn dev nên bật ngay.
Ten July 2026 reports on Claude Code, Cursor, Codex, ZCode and more — cost hacks ($42.21 to $4.51), 90% scanner evasion, and Cursor's $60B SpaceX rumor.

OpenAI API vs DeepSeek V4 Flash: real bills show a 40-42x cut ($18,000 to $450/mo). July 2026 math on when the switch is worth the migration time.

Across 7 July 2026 reports, Claude Fable 5 leads SWE-Bench Pro at 80.3% versus Grok 4.5, GPT-5.6 Sol, and Sonnet 5. Where each actually wins.

Sonnet 5 beats Sonnet 4.6 by 13-15% through Aug 31, 2026 — then costs 30% more after the price reverts and its tokenizer keeps burning extra tokens.

Eight published June 2026 benchmarks compared: Claude Opus 4.8, GPT-5.5, Fable 5, GLM-5.2, Gemini 3.1 Pro. The 22-point SWE-bench spread that nobody tables.

GLM-5.2 costs an estimated $0.50/1M input tokens vs Claude Sonnet 4.6 at $3/1M — a 6x gap. At Heavy workload, switching recovers the 10-hour migration cost in 2.3 months.

Across 8 June 2026 studies of LLM-as-Judge tools and methods, identical-prompt runs disagree like coin flips and brand bias skews 3 commercial judges.

Copilot switched to token-based AI Credits on June 1, 2026. Here's when the math breaks: Copilot Pro hits overage at 660+ credits/month; Medium workload costs $61/mo — $27 more than Pro Plus.

Anthropic shipped Claude Fable 5 on June 9, 2026 at $10/$50 per 1M tokens with a 1M context window. Eight launch reports compared in one place.

Aggregating 10 reports from May-June 2026 on Ollama v0.24.0, vLLM v0.21.0, self-hosted costs from $5 to $32/month, and the ~6x throughput gap.

Claude Opus 4.8 runs $3,300/mo vs DeepSeek's $54 at Heavy workload. Here's the break-even math — and when Opus earns its 61x token premium.

Across 10 May 2026 benchmarks, frontier AI agents averaged below 60 percent on production tasks. Codex CLI hit 82.7 percent. ITBench fell under 50.

Claude Sonnet API ($3/1M tokens) vs self-hosted Llama 3.2 90B (~$20/mo). The math flips at 303 prompts/day — self-hosting saves $46–$600/mo above that threshold.
An aggregation of 8 May 2026 reports on the terminal coding CLI ecosystem: a toolkit benchmark of 80/100, a 10x model price spread, a 1/160th self-host cost claim.

Braintrust costs $249/mo vs LangSmith's $99/mo. Is the $150/mo premium justified? Break-even math for solo devs, small teams, and scaling AI products.

Across 9 engineering blogs and benchmarks from May 2026, the failure modes of Claude Code, Cursor, Copilot, and Codex now have names and fixes.

